General introduction: Survival on the RMS Titanic
Przemyslaw Biecek
2023-01-14
Source:vignettes/vignette_titanic.Rmd
vignette_titanic.RmdData for Titanic survival
Let’s see an example for DALEX package for
classification models for the survival problem for Titanic dataset. Here
we are using a dataset titanic_imputed avaliable in the
DALEX package. Note that this data was copied from the
stablelearner package and changed for practicality.
#> gender age class embarked fare sibsp parch survived
#> 1 male 42 3rd Southampton 7.11 0 0 0
#> 2 male 13 3rd Southampton 20.05 0 2 0
#> 3 male 16 3rd Southampton 20.05 1 1 0
#> 4 female 39 3rd Southampton 20.05 1 1 1
#> 5 female 16 3rd Southampton 7.13 0 0 1
#> 6 male 25 3rd Southampton 7.13 0 0 1Model for Titanic survival
Ok, now it’s time to create a model. Let’s use the Random Forest model.
# prepare model
library("ranger")
model_titanic_rf <- ranger(survived ~ gender + age + class + embarked +
fare + sibsp + parch,
data = titanic_imputed, probability = TRUE)
model_titanic_rf#> Ranger result
#>
#> Call:
#> ranger(survived ~ gender + age + class + embarked + fare + sibsp + parch, data = titanic_imputed, probability = TRUE)
#>
#> Type: Probability estimation
#> Number of trees: 500
#> Sample size: 2207
#> Number of independent variables: 7
#> Mtry: 2
#> Target node size: 10
#> Variable importance mode: none
#> Splitrule: gini
#> OOB prediction error (Brier s.): 0.1423142Explainer for Titanic survival
The third step (it’s optional but useful) is to create a
DALEX explainer for random forest model.
library("DALEX")
explain_titanic_rf <- explain(model_titanic_rf,
data = titanic_imputed[,-8],
y = titanic_imputed[,8],
label = "Random Forest")#> Preparation of a new explainer is initiated
#> -> model label : Random Forest
#> -> data : 2207 rows 7 cols
#> -> target variable : 2207 values
#> -> predict function : yhat.ranger will be used ( default )
#> -> predicted values : No value for predict function target column. ( default )
#> -> model_info : package ranger , ver. 0.14.1 , task classification ( default )
#> -> predicted values : numerical, min = 0.0162592 , mean = 0.3219181 , max = 0.9889939
#> -> residual function : difference between y and yhat ( default )
#> -> residuals : numerical, min = -0.7763972 , mean = 0.0002387022 , max = 0.8771215
#> A new explainer has been created!Model Level Feature Importance
Use the feature_importance() explainer to present
importance of particular features. Note that
type = "difference" normalizes dropouts, and now they all
start in 0.
library("ingredients")
fi_rf <- feature_importance(explain_titanic_rf)
head(fi_rf)#> variable mean_dropout_loss label
#> 1 _full_model_ 0.3414379 Random Forest
#> 2 parch 0.3519820 Random Forest
#> 3 sibsp 0.3523238 Random Forest
#> 4 embarked 0.3530639 Random Forest
#> 5 age 0.3775351 Random Forest
#> 6 fare 0.3832377 Random Forest
plot(fi_rf)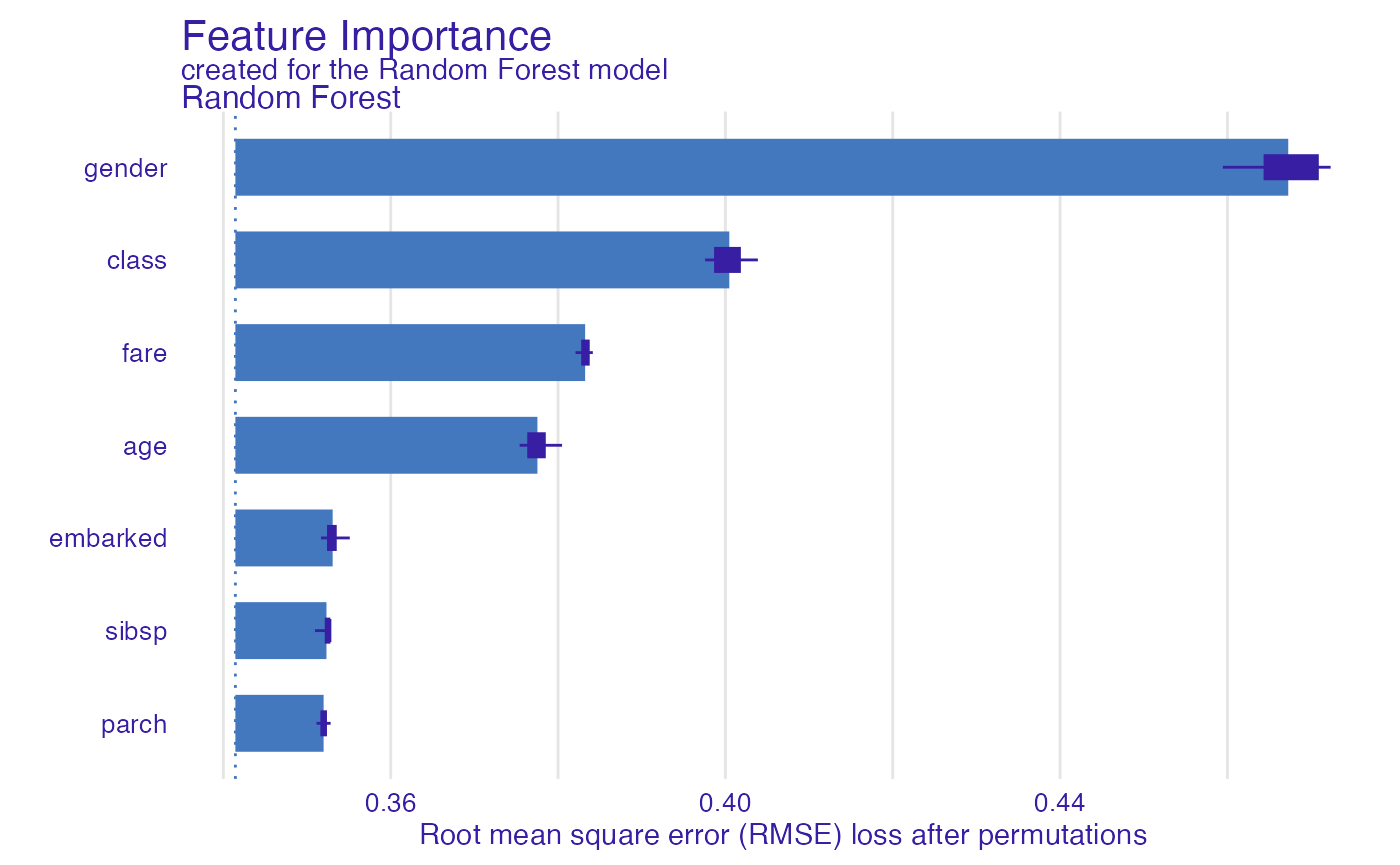
Feature effects
As we see the most important feature is gender. Next
three importnat features are class, age and
fare. Let’s see the link between model response and these
features.
Such univariate relation can be calculated with
partial_dependence().
age
Kids 5 years old and younger have much higher survival probability.
Partial Dependence Profiles
pp_age <- partial_dependence(explain_titanic_rf, variables = c("age", "fare"))
head(pp_age)#> Top profiles :
#> _vname_ _label_ _x_ _yhat_ _ids_
#> 1 fare Random Forest 0.0000000 0.3596720 0
#> 2 age Random Forest 0.1666667 0.5371610 0
#> 3 age Random Forest 2.0000000 0.5760988 0
#> 4 age Random Forest 4.0000000 0.5908485 0
#> 5 fare Random Forest 6.1793080 0.3082799 0
#> 6 age Random Forest 7.0000000 0.5440191 0
plot(pp_age)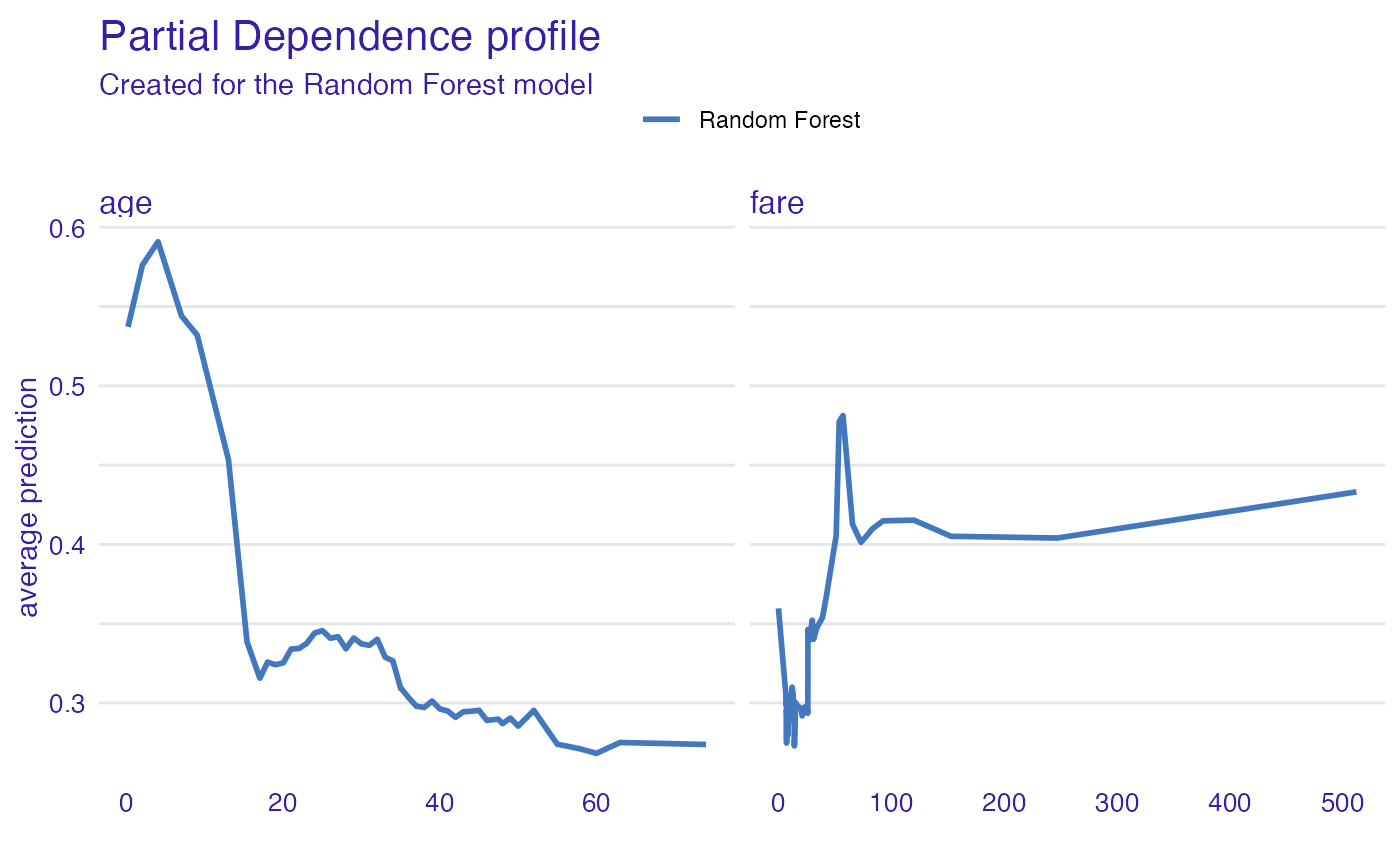
Conditional Dependence Profiles
cp_age <- conditional_dependence(explain_titanic_rf, variables = c("age", "fare"))
plot(cp_age)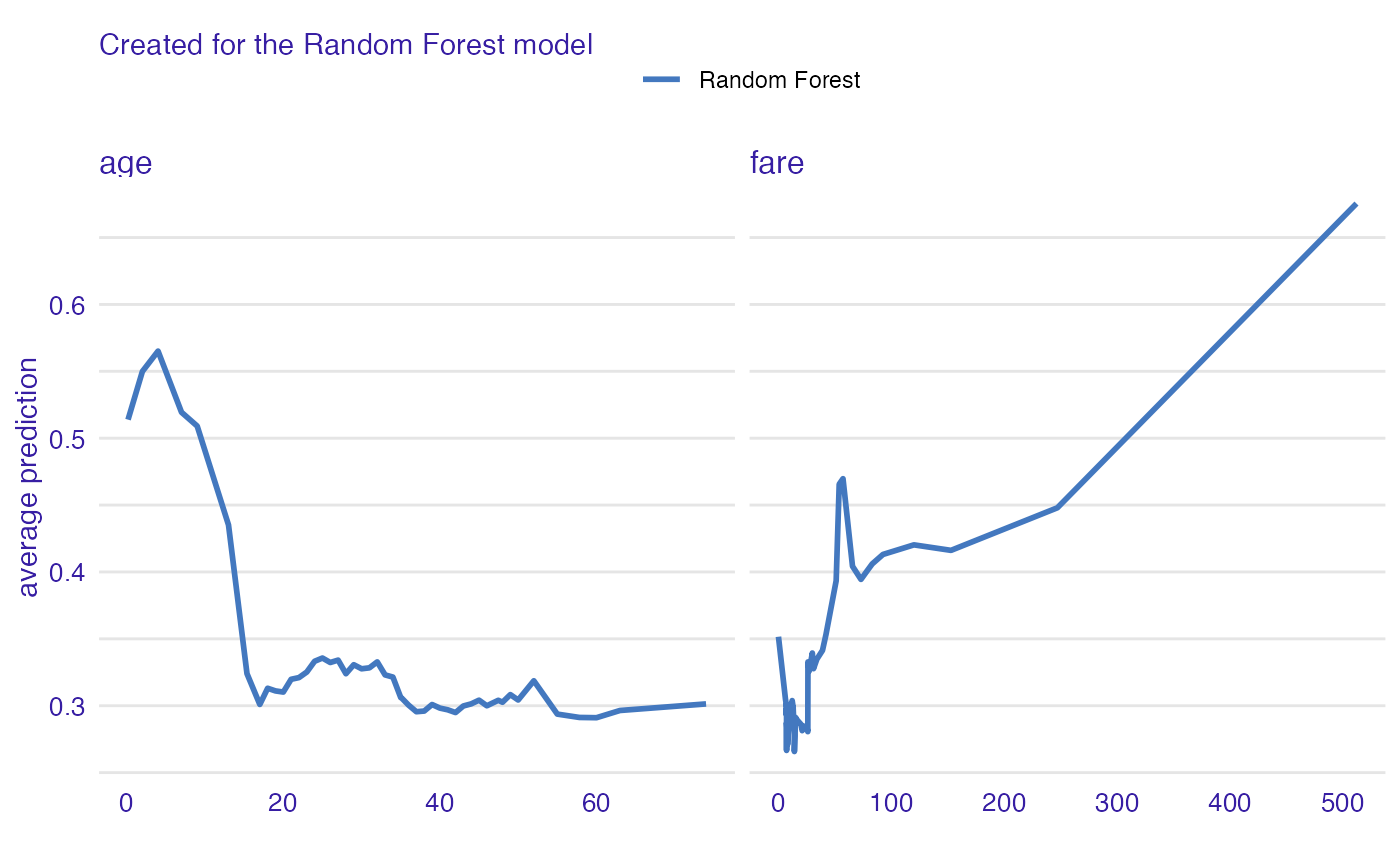
Accumulated Local Effect Profiles
ap_age <- accumulated_dependence(explain_titanic_rf, variables = c("age", "fare"))
plot(ap_age)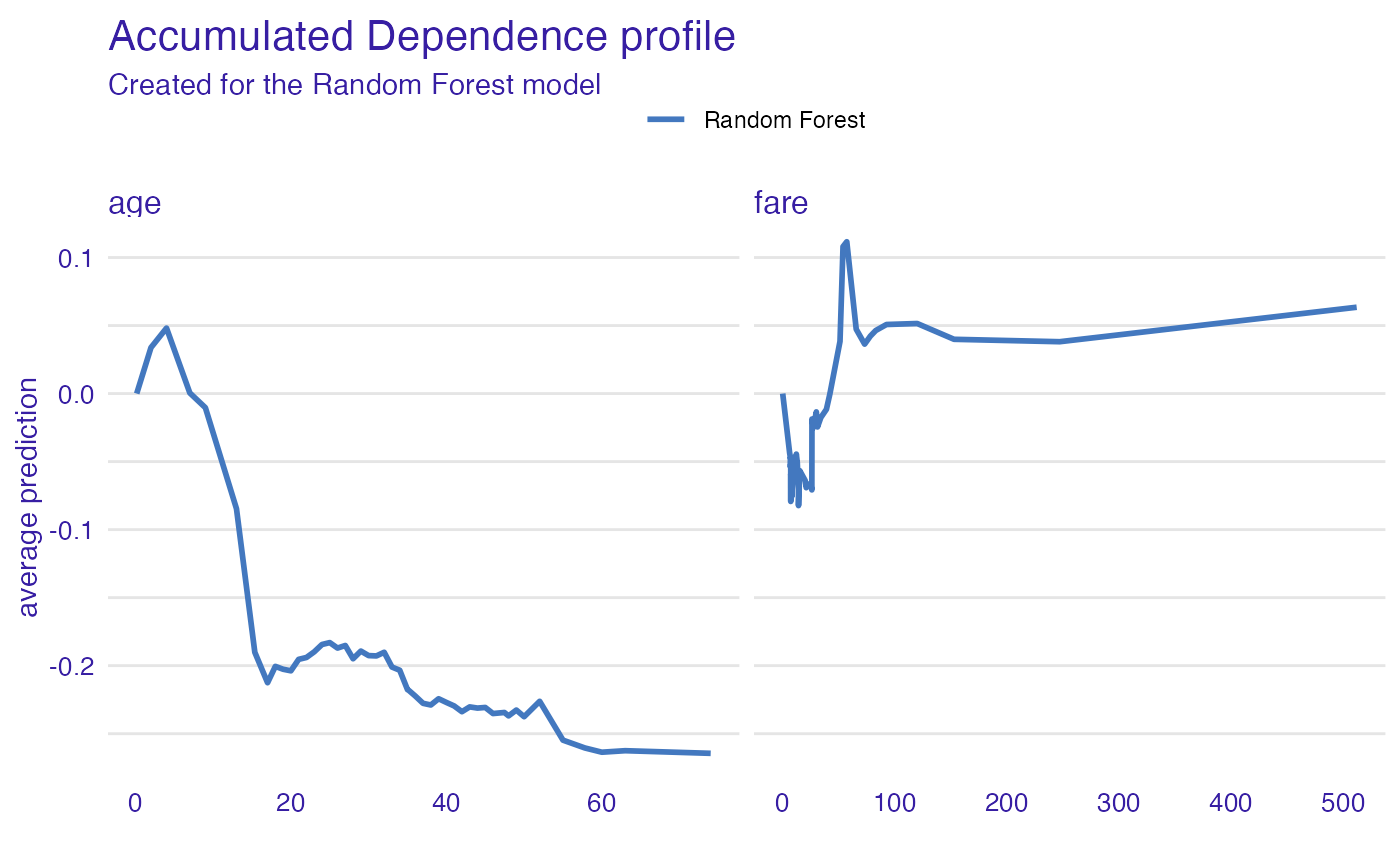
Instance level explanations
Let’s see break down explanation for model predictions for 8 years old male from 1st class that embarked from port C.
First Ceteris Paribus Profiles for numerical variables
new_passanger <- data.frame(
class = factor("1st", levels = c("1st", "2nd", "3rd", "deck crew", "engineering crew", "restaurant staff", "victualling crew")),
gender = factor("male", levels = c("female", "male")),
age = 8,
sibsp = 0,
parch = 0,
fare = 72,
embarked = factor("Southampton", levels = c("Belfast", "Cherbourg", "Queenstown", "Southampton"))
)
sp_rf <- ceteris_paribus(explain_titanic_rf, new_passanger)
plot(sp_rf) +
show_observations(sp_rf)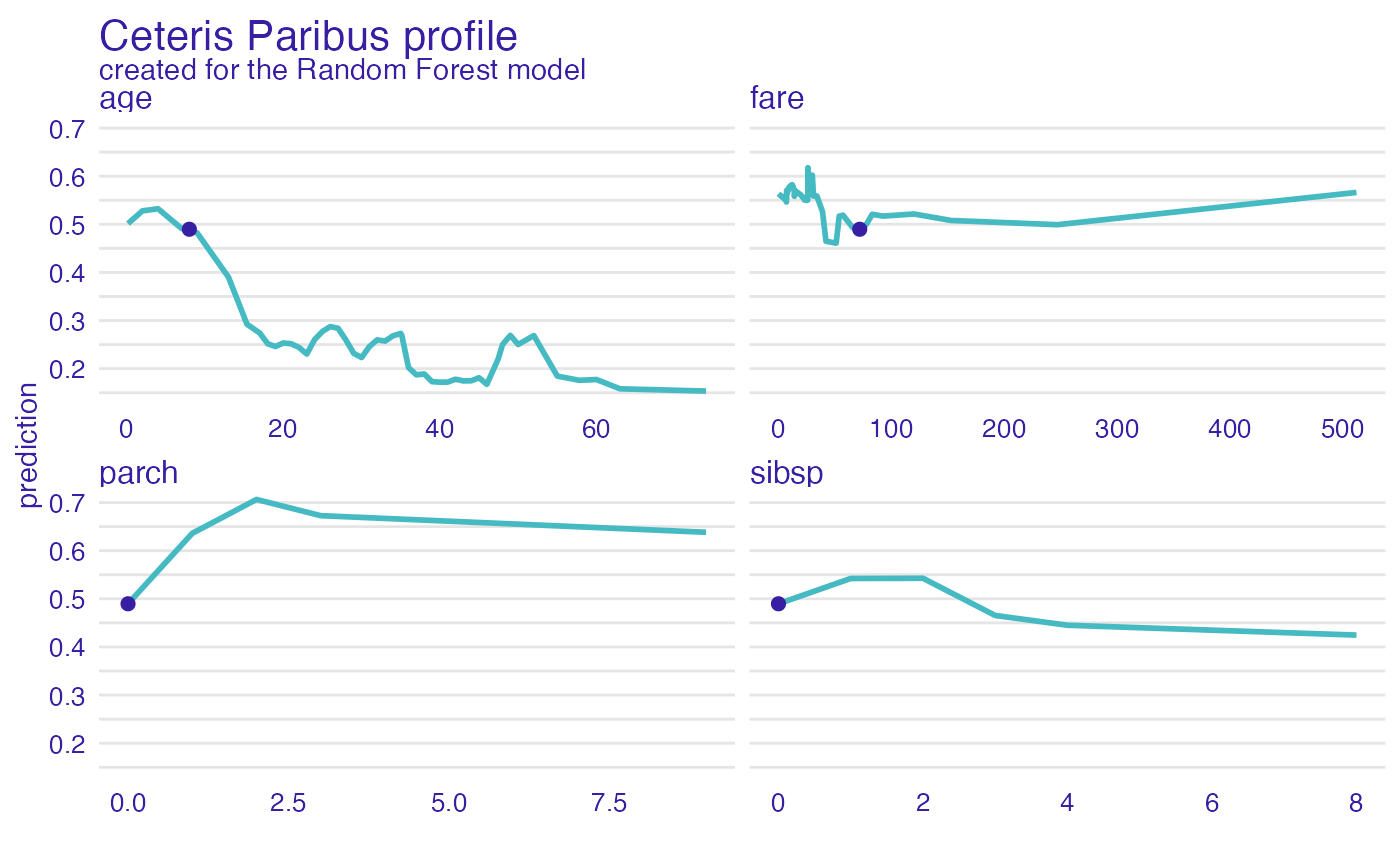
And for selected categorical variables. Note, that sibsp is numerical but here is presented as a categorical variable.
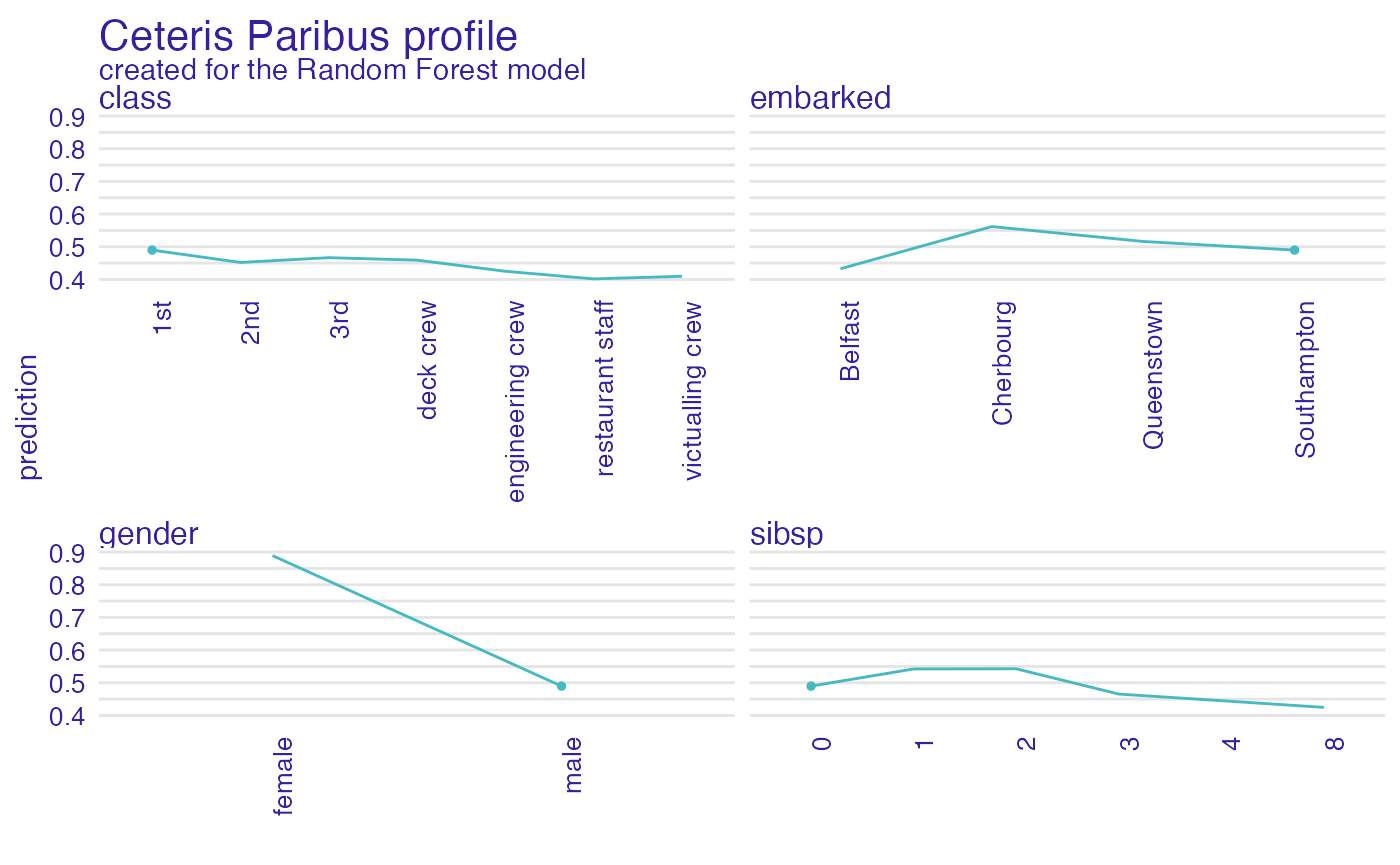
It looks like the most important feature for this passenger is
age and sex. After all his odds for survival
are higher than for the average passenger. Mainly because of the young
age and despite of being a male.
Profile clustering
passangers <- select_sample(titanic, n = 100)
sp_rf <- ceteris_paribus(explain_titanic_rf, passangers)
clust_rf <- cluster_profiles(sp_rf, k = 3)
head(clust_rf)#> Top profiles :
#> _vname_ _label_ _x_ _cluster_ _yhat_ _ids_
#> 1 fare Random Forest_1 0.0000000 1 0.2339843 0
#> 2 parch Random Forest_1 0.0000000 1 0.1671031 0
#> 3 sibsp Random Forest_1 0.0000000 1 0.1701528 0
#> 4 age Random Forest_1 0.1666667 1 0.4576590 0
#> 5 parch Random Forest_1 1.0000000 1 0.2386795 0
#> 6 sibsp Random Forest_1 1.0000000 1 0.1507614 0
plot(sp_rf, alpha = 0.1) +
show_aggregated_profiles(clust_rf, color = "_label_", size = 2)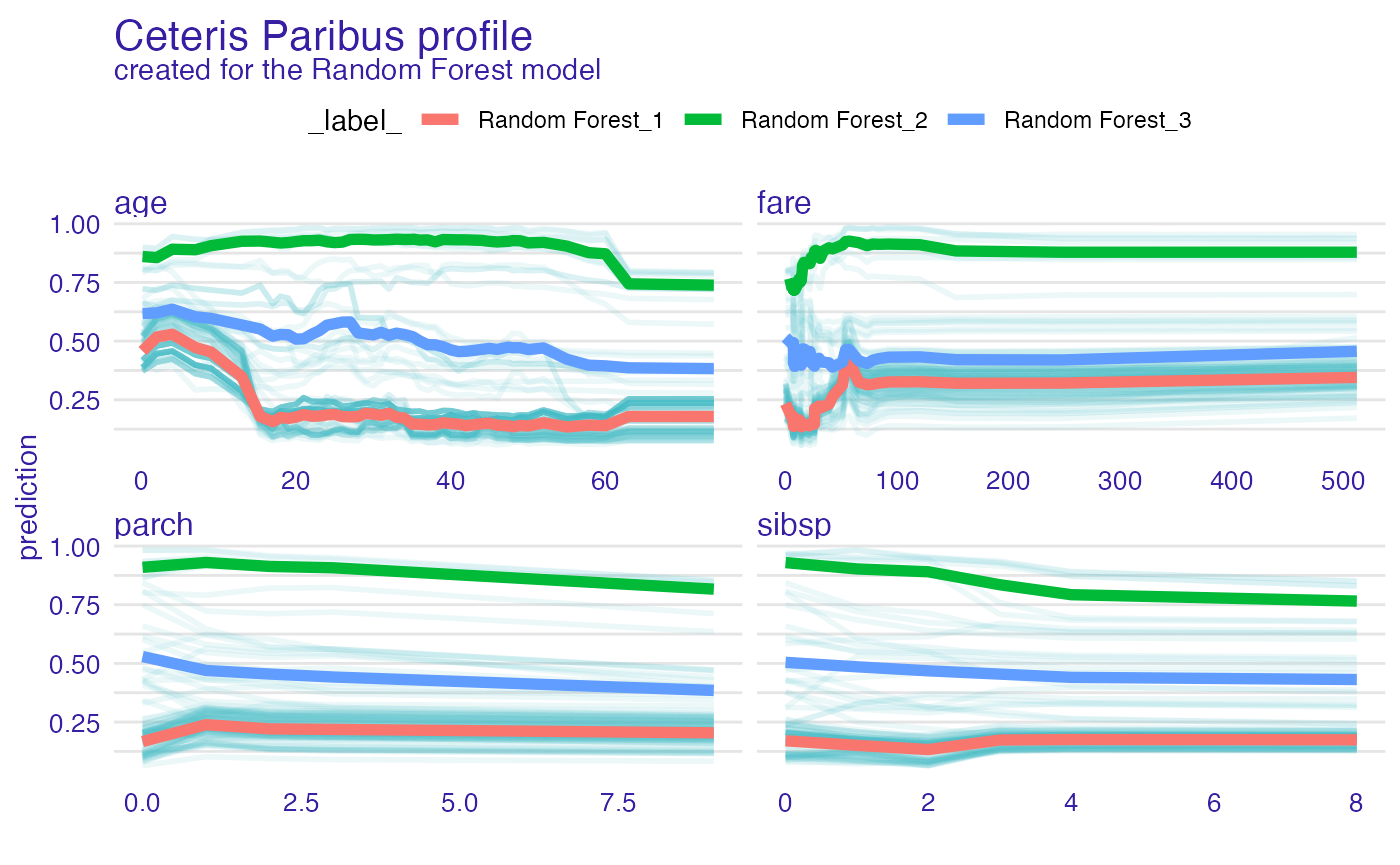
Session info
#> R version 4.2.2 (2022-10-31)
#> Platform: x86_64-apple-darwin17.0 (64-bit)
#> Running under: macOS Big Sur ... 10.16
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib
#>
#> locale:
#> [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ingredients_2.3.0 ranger_0.14.1 DALEX_2.4.2
#>
#> loaded via a namespace (and not attached):
#> [1] Rcpp_1.0.9 highr_0.10 bslib_0.4.2 compiler_4.2.2
#> [5] pillar_1.8.1 jquerylib_0.1.4 tools_4.2.2 digest_0.6.31
#> [9] lattice_0.20-45 jsonlite_1.8.4 evaluate_0.19 memoise_2.0.1
#> [13] lifecycle_1.0.3 tibble_3.1.8 gtable_0.3.1 pkgconfig_2.0.3
#> [17] rlang_1.0.6 Matrix_1.5-1 cli_3.6.0 yaml_2.3.6
#> [21] pkgdown_2.0.7 xfun_0.36 fastmap_1.1.0 withr_2.5.0
#> [25] stringr_1.5.0 knitr_1.41 desc_1.4.2 fs_1.5.2
#> [29] vctrs_0.5.1 sass_0.4.4 systemfonts_1.0.4 rprojroot_2.0.3
#> [33] grid_4.2.2 glue_1.6.2 R6_2.5.1 textshaping_0.3.6
#> [37] fansi_1.0.3 rmarkdown_2.19 farver_2.1.1 purrr_1.0.1
#> [41] ggplot2_3.4.0 magrittr_2.0.3 scales_1.2.1 htmltools_0.5.4
#> [45] colorspace_2.0-3 labeling_0.4.2 ragg_1.2.5 utf8_1.2.2
#> [49] stringi_1.7.12 munsell_0.5.0 cachem_1.0.6