This function calculates aggregates of ceteris paribus profiles based on hierarchical clustering.
cluster_profiles(
x,
...,
aggregate_function = mean,
variable_type = "numerical",
center = FALSE,
k = 3,
variables = NULL
)Arguments
- x
a ceteris paribus explainer produced with function
ceteris_paribus()- ...
other explainers that shall be plotted together
- aggregate_function
a function for profile aggregation. By default it's
mean- variable_type
a character. If
numericalthen only numerical variables will be computed. Ifcategoricalthen only categorical variables will be computed.- center
shall profiles be centered before clustering
- k
number of clusters for the hclust function
- variables
if not
NULLthen onlyvariableswill be presented
Value
an object of the class aggregated_profiles_explainer
Details
Find more detailes in the Clustering Profiles Chapter.
References
Explanatory Model Analysis. Explore, Explain, and Examine Predictive Models. https://ema.drwhy.ai/
Examples
library("DALEX")
library("ingredients")
selected_passangers <- select_sample(titanic_imputed, n = 100)
model_titanic_glm <- glm(survived ~ gender + age + fare,
data = titanic_imputed, family = "binomial")
explain_titanic_glm <- explain(model_titanic_glm,
data = titanic_imputed[,-8],
y = titanic_imputed[,8])
#> Preparation of a new explainer is initiated
#> -> model label : lm ( default )
#> -> data : 2207 rows 7 cols
#> -> target variable : 2207 values
#> -> predict function : yhat.glm will be used ( default )
#> -> predicted values : No value for predict function target column. ( default )
#> -> model_info : package stats , ver. 4.2.2 , task classification ( default )
#> -> predicted values : numerical, min = 0.1490412 , mean = 0.3221568 , max = 0.9878987
#> -> residual function : difference between y and yhat ( default )
#> -> residuals : numerical, min = -0.8898433 , mean = 4.198546e-13 , max = 0.8448637
#> A new explainer has been created!
cp_rf <- ceteris_paribus(explain_titanic_glm, selected_passangers)
clust_rf <- cluster_profiles(cp_rf, k = 3, variables = "age")
plot(clust_rf)
 # \donttest{
library("ranger")
model_titanic_rf <- ranger(survived ~., data = titanic_imputed, probability = TRUE)
explain_titanic_rf <- explain(model_titanic_rf,
data = titanic_imputed[,-8],
y = titanic_imputed[,8],
label = "ranger forest",
verbose = FALSE)
cp_rf <- ceteris_paribus(explain_titanic_rf, selected_passangers)
cp_rf
#> Top profiles :
#> gender age class embarked fare sibsp parch _yhat_
#> 515 female 45 2nd Southampton 10.1000 0 0 0.8125426
#> 515.1 male 45 2nd Southampton 10.1000 0 0 0.1098901
#> 604 female 17 3rd Southampton 7.1701 1 0 0.4618520
#> 604.1 male 17 3rd Southampton 7.1701 1 0 0.1108578
#> 1430 female 25 engineering crew Southampton 0.0000 0 0 0.7440738
#> 1430.1 male 25 engineering crew Southampton 0.0000 0 0 0.2346546
#> _vname_ _ids_ _label_
#> 515 gender 515 ranger forest
#> 515.1 gender 515 ranger forest
#> 604 gender 604 ranger forest
#> 604.1 gender 604 ranger forest
#> 1430 gender 1430 ranger forest
#> 1430.1 gender 1430 ranger forest
#>
#>
#> Top observations:
#> gender age class embarked fare sibsp parch _yhat_
#> 515 male 45 2nd Southampton 10.1000 0 0 0.1098901
#> 604 male 17 3rd Southampton 7.1701 1 0 0.1108578
#> 1430 male 25 engineering crew Southampton 0.0000 0 0 0.2346546
#> 865 male 20 3rd Cherbourg 7.0406 0 0 0.1124048
#> 452 female 17 3rd Queenstown 7.1408 0 0 0.6530898
#> 1534 male 38 victualling crew Southampton 0.0000 0 0 0.1729712
#> _label_ _ids_
#> 515 ranger forest 1
#> 604 ranger forest 2
#> 1430 ranger forest 3
#> 865 ranger forest 4
#> 452 ranger forest 5
#> 1534 ranger forest 6
pdp_rf <- aggregate_profiles(cp_rf, variables = "age")
head(pdp_rf)
#> Top profiles :
#> _vname_ _label_ _x_ _yhat_ _ids_
#> 1 age ranger forest 0.1666667 0.5218831 0
#> 2 age ranger forest 2.0000000 0.5590009 0
#> 3 age ranger forest 4.0000000 0.5760272 0
#> 4 age ranger forest 7.0000000 0.5150417 0
#> 5 age ranger forest 9.0000000 0.4988154 0
#> 6 age ranger forest 13.0000000 0.4224053 0
clust_rf <- cluster_profiles(cp_rf, k = 3, variables = "age")
head(clust_rf)
#> Top profiles :
#> _vname_ _label_ _x_ _cluster_ _yhat_ _ids_
#> 1 age ranger forest_1 0.1666667 1 0.4682033 0
#> 2 age ranger forest_1 2.0000000 1 0.5174090 0
#> 3 age ranger forest_1 4.0000000 1 0.5340391 0
#> 4 age ranger forest_1 7.0000000 1 0.4630265 0
#> 5 age ranger forest_1 9.0000000 1 0.4410660 0
#> 6 age ranger forest_1 13.0000000 1 0.3446678 0
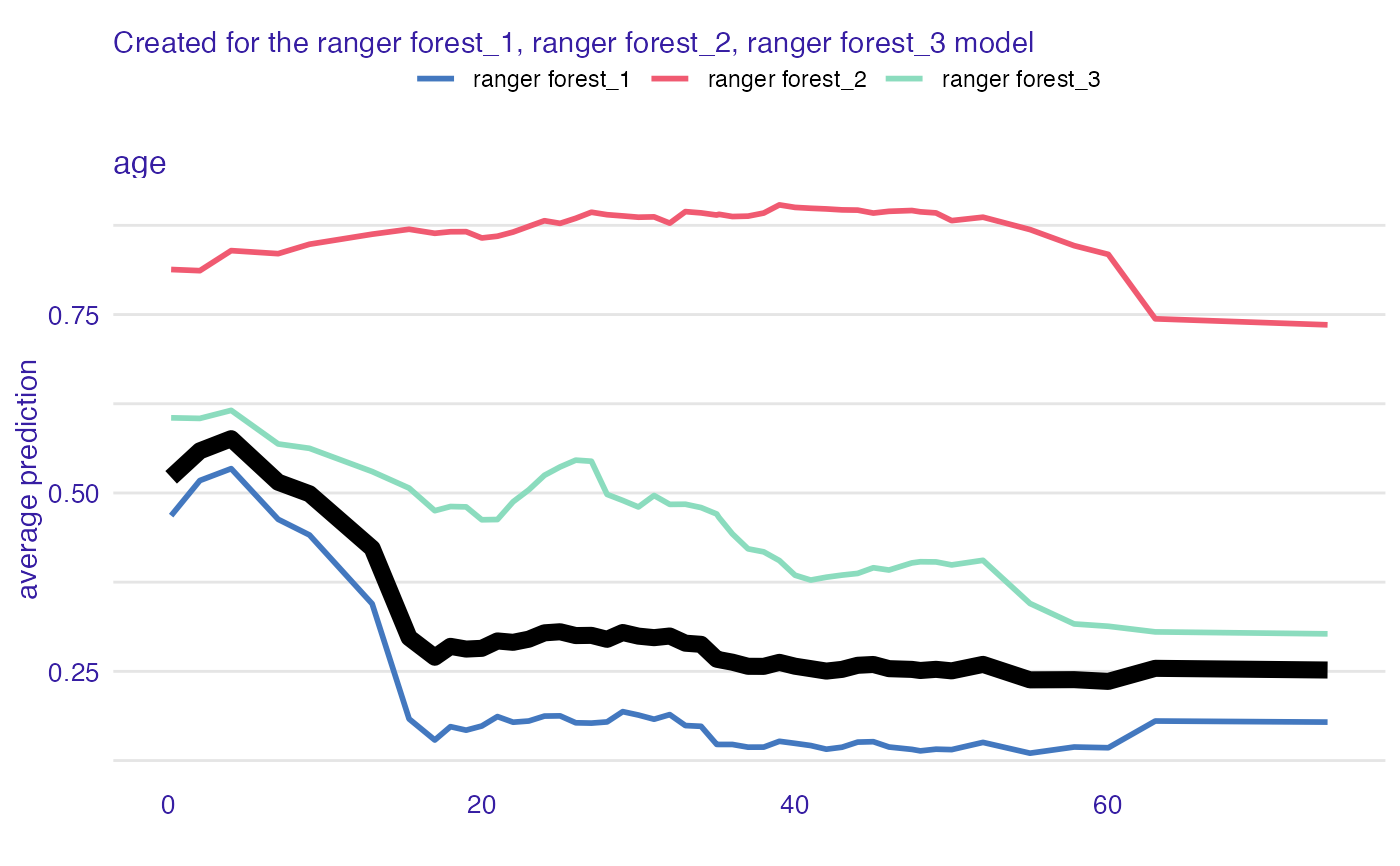
plot(clust_rf, color = "_label_") +
show_aggregated_profiles(pdp_rf, color = "black", size = 3)
# \donttest{
library("ranger")
model_titanic_rf <- ranger(survived ~., data = titanic_imputed, probability = TRUE)
explain_titanic_rf <- explain(model_titanic_rf,
data = titanic_imputed[,-8],
y = titanic_imputed[,8],
label = "ranger forest",
verbose = FALSE)
cp_rf <- ceteris_paribus(explain_titanic_rf, selected_passangers)
cp_rf
#> Top profiles :
#> gender age class embarked fare sibsp parch _yhat_
#> 515 female 45 2nd Southampton 10.1000 0 0 0.8125426
#> 515.1 male 45 2nd Southampton 10.1000 0 0 0.1098901
#> 604 female 17 3rd Southampton 7.1701 1 0 0.4618520
#> 604.1 male 17 3rd Southampton 7.1701 1 0 0.1108578
#> 1430 female 25 engineering crew Southampton 0.0000 0 0 0.7440738
#> 1430.1 male 25 engineering crew Southampton 0.0000 0 0 0.2346546
#> _vname_ _ids_ _label_
#> 515 gender 515 ranger forest
#> 515.1 gender 515 ranger forest
#> 604 gender 604 ranger forest
#> 604.1 gender 604 ranger forest
#> 1430 gender 1430 ranger forest
#> 1430.1 gender 1430 ranger forest
#>
#>
#> Top observations:
#> gender age class embarked fare sibsp parch _yhat_
#> 515 male 45 2nd Southampton 10.1000 0 0 0.1098901
#> 604 male 17 3rd Southampton 7.1701 1 0 0.1108578
#> 1430 male 25 engineering crew Southampton 0.0000 0 0 0.2346546
#> 865 male 20 3rd Cherbourg 7.0406 0 0 0.1124048
#> 452 female 17 3rd Queenstown 7.1408 0 0 0.6530898
#> 1534 male 38 victualling crew Southampton 0.0000 0 0 0.1729712
#> _label_ _ids_
#> 515 ranger forest 1
#> 604 ranger forest 2
#> 1430 ranger forest 3
#> 865 ranger forest 4
#> 452 ranger forest 5
#> 1534 ranger forest 6
pdp_rf <- aggregate_profiles(cp_rf, variables = "age")
head(pdp_rf)
#> Top profiles :
#> _vname_ _label_ _x_ _yhat_ _ids_
#> 1 age ranger forest 0.1666667 0.5218831 0
#> 2 age ranger forest 2.0000000 0.5590009 0
#> 3 age ranger forest 4.0000000 0.5760272 0
#> 4 age ranger forest 7.0000000 0.5150417 0
#> 5 age ranger forest 9.0000000 0.4988154 0
#> 6 age ranger forest 13.0000000 0.4224053 0
clust_rf <- cluster_profiles(cp_rf, k = 3, variables = "age")
head(clust_rf)
#> Top profiles :
#> _vname_ _label_ _x_ _cluster_ _yhat_ _ids_
#> 1 age ranger forest_1 0.1666667 1 0.4682033 0
#> 2 age ranger forest_1 2.0000000 1 0.5174090 0
#> 3 age ranger forest_1 4.0000000 1 0.5340391 0
#> 4 age ranger forest_1 7.0000000 1 0.4630265 0
#> 5 age ranger forest_1 9.0000000 1 0.4410660 0
#> 6 age ranger forest_1 13.0000000 1 0.3446678 0
plot(clust_rf, color = "_label_") +
show_aggregated_profiles(pdp_rf, color = "black", size = 3)
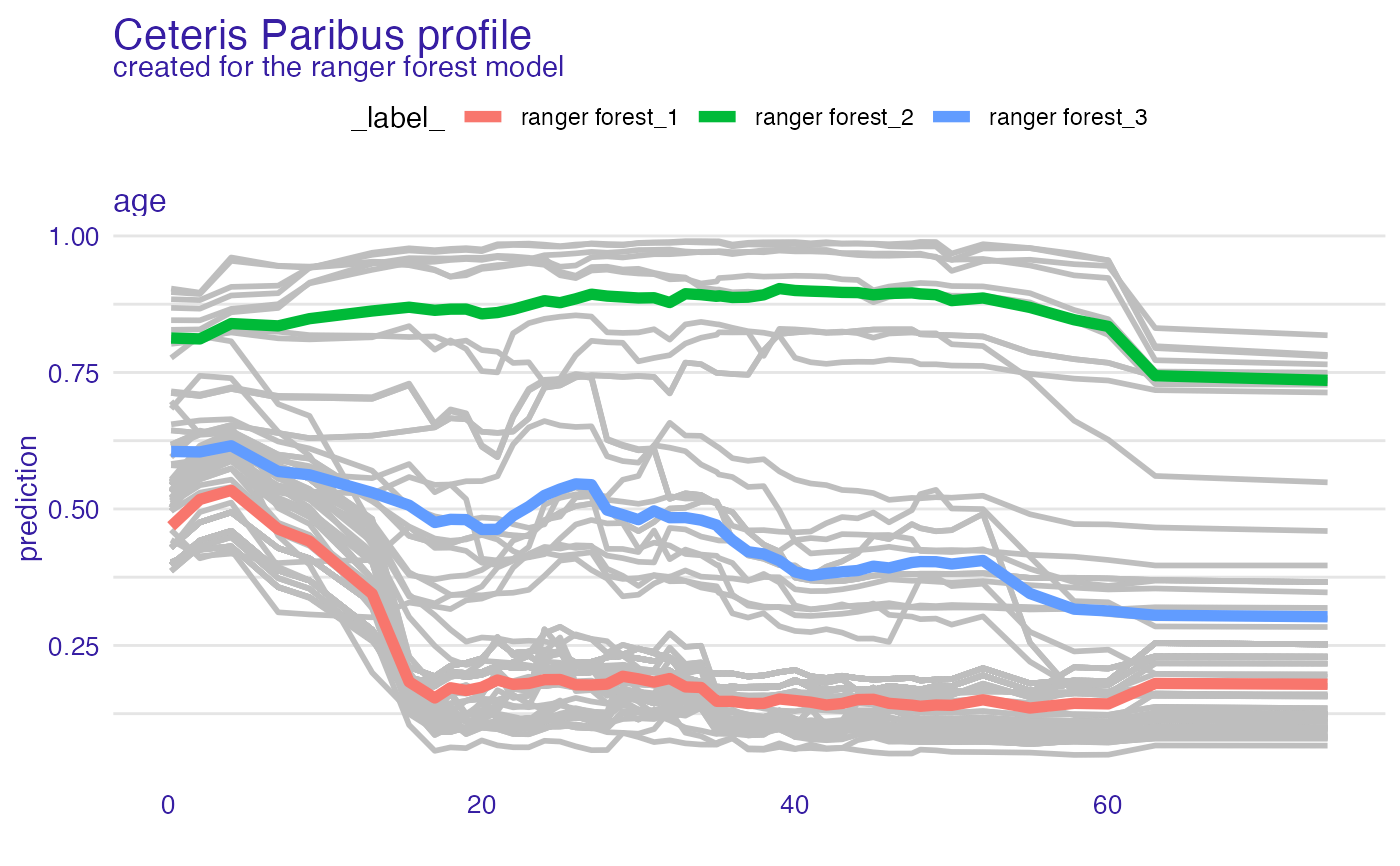
 plot(cp_rf, color = "grey", variables = "age") +
show_aggregated_profiles(clust_rf, color = "_label_", size = 2)
plot(cp_rf, color = "grey", variables = "age") +
show_aggregated_profiles(clust_rf, color = "_label_", size = 2)
 clust_rf <- cluster_profiles(cp_rf, k = 3, center = TRUE, variables = "age")
head(clust_rf)
#> Top profiles :
#> _vname_ _label_ _x_ _cluster_ _yhat_ _ids_
#> 1 age ranger forest_1 0.1666667 1 0.5395164 0
#> 2 age ranger forest_1 2.0000000 1 0.5974616 0
#> 3 age ranger forest_1 4.0000000 1 0.6149357 0
#> 4 age ranger forest_1 7.0000000 1 0.5437661 0
#> 5 age ranger forest_1 9.0000000 1 0.5179230 0
#> 6 age ranger forest_1 13.0000000 1 0.4091254 0
# }
clust_rf <- cluster_profiles(cp_rf, k = 3, center = TRUE, variables = "age")
head(clust_rf)
#> Top profiles :
#> _vname_ _label_ _x_ _cluster_ _yhat_ _ids_
#> 1 age ranger forest_1 0.1666667 1 0.5395164 0
#> 2 age ranger forest_1 2.0000000 1 0.5974616 0
#> 3 age ranger forest_1 4.0000000 1 0.6149357 0
#> 4 age ranger forest_1 7.0000000 1 0.5437661 0
#> 5 age ranger forest_1 9.0000000 1 0.5179230 0
#> 6 age ranger forest_1 13.0000000 1 0.4091254 0
# }