Overview
Have you just created a model which is biased against some subgroup? Or have you just tried to fight the bias, but models performance dropped significantly? Use FairPAN to create neural network model that provides fair predictions and achieves outstanding performance! With pretrain() you can create or provide your own neural networks and then use them in fair_train() to achieve fair outcomes. R package FairPAN additionally allows you to use lots of DALEX and fairmodels functions such as DALEX::model_performance() or fairmodels::fairness_check().
If you have problems with the training process remember to use monitor parameter and plot_monitor function for parameter adjustments.
Check FairPAN Website!
Theoretical introduction
Introduction to Fairness
Consider the idea of the algorithm that has to predict whether giving credit to a person is risky or not. It is learning on real data of giving credits which were biased against females (historical fact). In that case, the model learns this bias, which is not only included in the simple sex variable but also is hidden inside other variables. Fairness enables us to detect such bias and handles a few methods to fight it. To learn more, I recommend the article ‘Fairmodels: A Flexible Tool For Bias Detection, Visualization, And Mitigation’ by Jakub Wisniewski and Przemysław Biecek.
Introduction to GANs
Generative Adversarial Networks are two neural networks that learn together. The Generator has to generate new samples that are indistinguishable from original data and the adversarial has to distinguish if the observation is original or generated. The generator is punished whenever the adversarial makes the correct prediction. After such process generator eventually learns how to make indistinguishable predictions and adversaries’ accuracy drops down to 50% when a model cannot distinguish the two classes. The idea of GANs was proposed in Generative Adversarial Nets, Ian Goodfellow.
FairPAN
FairPANs are the solution to bring fairness into neural networks. We mimic the GANs by subsetting generator with classifier (predictor) and adversarial has to predict the sensitive value (such as sex, race, etc) from the output of the predictor. This process eventually leads the classifier to make predictions with indistinguishable sensitive values. The idea comes from blogs: Towards fairness in ML with adversarial networks, Stijn Tonk and Fairness in Machine Learning with PyTorch, Henk Griffoen however, our implementation in R offers slightly different solutions. And the exact idea behind using GANs for Fairness is described in Achieving Fairness through Adversarial Learning: an Application to Recidivism Prediction, Christina Wadsworth, Francesca Vera, Chris Piech.
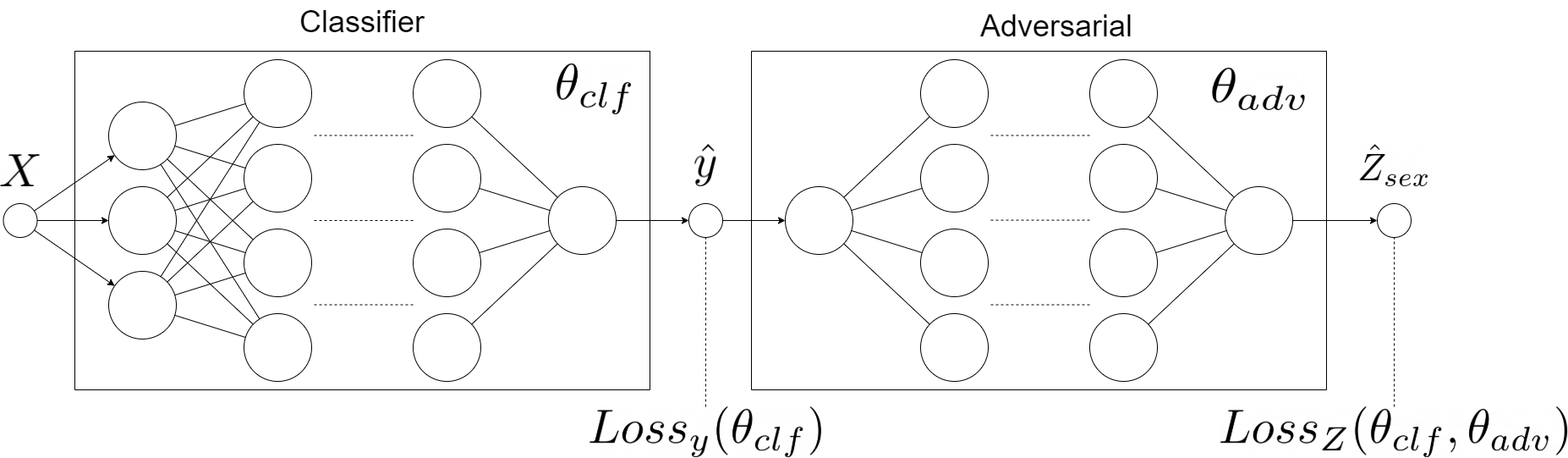
The diagram above represents the architecture of our model and is strongly inspired by aforementioned blogs.
Custom Loss Function
The crucial part of this model is the metric we use to engage the two models into a zero-sum game. This is captured by the following objective function:
So, it learns to minimize its prediction losses while maximizing that of the adversarial (due to lambda being positive and minimizing a negated loss is the same as maximizing it). The objective during the game is simpler for the adversarial: predict sex based on the income level predictions of the classifier. This is captured in the following objective function:
The adversarial does not care about the prediction accuracy of the classifier. It is only concerned with minimizing its prediction losses. Firstly we pretrain classifier and adversarial. Later we begin the proper PAN training with both networks: we train the adversarial, provide its loss to the classifier, and after that, we train the classifier. This method shall lead us to fair predictions of the FairPAN model.
Why?
Regular mitigation techniques tend to worsen performance of the classifier a lot by decreasing accuracy for example, whereas FairPAN has no such drawback and worsening of the performance is really small. Moreover, our package is very flexible because it enables to provide your own neural networks, but also to create one with our functions. The outcomes are also created with the usage of DALEX and fairmodels, so one can use their methods and visualizations. Additionally the workflow of the package is really simple and clean, because of multiple features available for user, such as preprocess function.
Installation
Install the developer version from GitHub:
devtools::install_github("ModelOriented/FairPAN",build_vignettes = TRUE)Workflow
The graph below represents how the workflow inside the package looks like. Firstly we have to provide data and use preprocess() which creates all sets needed for this package to work. One can also skip that step, however it is not advisable to do so. Later we have to create a dataset_loader() which organises our data to be ready for torch usage. The nest step is really flexible, because we can choose whether we want to create our functions with the package openly via create_model() and pretrain_net(), hidden inside pretrain() or we want to provide neural networks create on our own, which can be pretrained or not, depending on our needs. It is extremely powerful, because we can provide some well known and pretrained classifiers. Later, we engage the fair_train() process which outcomes we can visualize by setting monitor to true and using plot_monitor(). Although we can finish the process at his spot, we can also analyse the outcomes a bit more with explain_pan() and use all DALEX functions on the returned explainer. This explainer can also be used to apply fairmodels::fairness_check() and other functions from this package.

Example
Achieve fairness and save performance!
library(fairpan)
adult <- fairmodels::adult
# ------------------- step 1 - prepare data ------------------------
data <- preprocess( data = adult,
target_name = "salary",
sensitive_name = "sex",
privileged = "Male",
discriminated = "Female",
drop_also = c("race"),
sample = 0.02,
train_size = 0.6,
test_size = 0.4,
validation_size = 0,
seed = 7
)
dev <- "cpu"
dsl <- dataset_loader(train_x = data$train_x,
train_y = data$train_y,
test_x = data$test_x,
test_y = data$test_y,
batch_size = 5,
dev = dev
)
# ------------ step 2 - create and pretrain models -----------------
models <- pretrain(clf_model = NULL,
adv_model = NULL,
clf_optimizer = NULL,
trained = FALSE,
train_x = data$train_x,
train_y = data$train_y,
sensitive_train = data$sensitive_train,
sensitive_test = data$sensitive_test,
batch_size = 5,
partition = 0.6,
neurons_clf = c(32, 32, 32),
neurons_adv = c(32, 32, 32),
dimension_clf = 2,
dimension_adv = 1,
learning_rate_clf = 0.001,
learning_rate_adv = 0.001,
n_ep_preclf = 10,
n_ep_preadv = 10,
dsl = dsl,
dev = dev,
verbose = TRUE,
monitor = TRUE
)
# --------------- step 3 - train for fairness --------------------
monitor <- fair_train( n_ep_pan = 17,
dsl = dsl,
clf_model = models$clf_model,
adv_model = models$adv_model,
clf_optimizer = models$clf_optimizer,
adv_optimizer = models$adv_optimizer,
dev = dev,
sensitive_train = data$sensitive_train,
sensitive_test = data$sensitive_test,
batch_size = 5,
learning_rate_adv = 0.001,
learning_rate_clf = 0.001,
lambda = 130,
verbose = TRUE,
monitor = TRUE
)
# --------- step 4 - prepare outcomes and plot them --------------
plot_monitor(STP = monitor$STP,
adversary_acc = monitor$adversary_acc,
adversary_losses = monitor$adversary_losses,
classifier_acc = monitor$classifier_acc)
exp_clf <- explain_pan(y = data$test_y,
model = models$clf_model,
label = "PAN",
data = data$data_test,
data_scaled = data$data_scaled_test,
batch_size = 5,
dev = dev,
verbose = TRUE
)
fobject <- fairmodels::fairness_check(exp_PAN,
protected = data$protected_test,
privileged = "Male",
verbose = TRUE)
plot(fobject)Fair training is flexible
pretrain function has optional parameters:
clf_modelnn_module describing classifiers neural network architectureadv_modelnn_module describing adversaries neural network architectureclf_optimizertorch object providing classifier optimizer from pretraintrainedsettles whether clf_model is trained or not
which enables users to provide their own and even pretrained neural network models.
On the other hand, you can use FairPAN package from the very beginning starting from data preprocessing with preprocess() function which provides every dataset that you will need for provided features.